Thursday, December 21, 2006
My OSDC 2006 Paper
At this years OSDC, I did a presentation titled Development of Mono Applications with Agile Languages. The agile languages I discussed were Boo and IronPython. I have presented at the last three OSDC's and this years topic generated the most feedback and post presentation discussion for me. The paper published in the proceedings can be downloaded from here.
ISAPI WSGI SVN has moved
Due to heavy ticket spam on the old SVN site http://isapi-wsgi.python-hosting.com, it would appear that the isapi-wsgi site has been taken off-line. A couple of months ago I started mirroring the SVN at http://isapi-wsgi.googlecode.com/svn/trunk/ so access to the source code is still available. Thank goodness for backups.
Tuesday, December 12, 2006
Is Linux ready for Inflight Entertainment?
Yesterday I flew to Malaysia on a MAS 747. It is a 8+ hour flight, but the plane has the individual movie/game consoles in the back of the seat headrest to allow me to catch up on all the movies I normally would never get to see. The only problem was that every 40-50 minutes, my console crashed. Not with the "blue screen of death", but with a Tux image and a crash trace. A few minutes later it would re-boot and the movie would continue. As a geek I do find reading a crash trace entertaining but for non-geeks, maybe not the best introduction to OSS.
Monday, December 04, 2006
More Blogger Beta Woes
Now the compose mode in browser editor has disappeared when creating and editting posts. You only understand how useful something is when it is taken away.
Also the Atom feed generation seems to continue to randomly decide I have modified posts that I haven't.
The joys of beta software.
Also the Atom feed generation seems to continue to randomly decide I have modified posts that I haven't.
The joys of beta software.
OSDC 2006 Starts on Wednesday
Flying down to Melbourne tomorrow for OSDC 2006. The program is looking very good and I am sure the topics will be mind expanding. My talk on Mono, Boo and IronPython is midday on the second day of the conference. Based on my experience at the last two OSDC conferences, I have to agree with Andy Todd's statement:
"I expect OSDC this year like last will be full of smart people sharing great ideas, prompting me to make promises to myself to look into things that I won’t have time to keep."
So once I am back from the conference, I need to do the posts I have promised some readers of this blog:
The Status of IronPython and Eggs
IronPython and WSGI
Then I need to find the time for all the other things OSDC will have got me excited about.
"I expect OSDC this year like last will be full of smart people sharing great ideas, prompting me to make promises to myself to look into things that I won’t have time to keep."
So once I am back from the conference, I need to do the posts I have promised some readers of this blog:
The Status of IronPython and Eggs
IronPython and WSGI
Then I need to find the time for all the other things OSDC will have got me excited about.
Thursday, November 23, 2006
IronPython and trace style debugging
When developing with IronPython under Windows, there is excellent debugger support via Visual Studio. But sometimes you just want to do simple trace style debugging, in other words, put some print statements in your code. This works well when developing an application you can run under the console but is problematic if the application is a service or ASP.NET handler. When developing similar applications with CPython under Windows, I used the win32trace.pyd/win32traceutil.py to achieve this.
From the win32 python docs:
So I decided you create something similar for IronPython. win32trace uses a memory mapped file for communication between the application and the trace collector. Since the only way I could find to use memory mapped files under CLI, relied on calls to unmanaged win32 api, I decided to use network UDP datagrams instead. Rather than writing something from scratch, I remembered a python script that I had used many years ago, creosote.py by Jeff Bauer. The original link to the script is broken, so I finally tracked a copy down in the Zope CVS. So I wrapped this code in a wrapper traceutil.py.
To use it, you just need to put this script in your IronPython or CPython path, and any output to stdout or stderr will be sent to the collector.
To start the collector:
If the following code is run as a script by IronPython or CPython:
the following would appear in the collector console running under .NET:
and the following would appear in the collector console running under Mono:
From the win32 python docs:
These modules allow one Python process to generate output via a "print" statement, and another unrelated Python process to display the data. This works even if the Python process generating the output is running under the context of a service, where more traditional means are not available. The module works on Windows 95 and Windows NT.
To enable this debugging, simply "import win32traceutil" somewhere in your program - thats it! This automatically re-directs the standard Python output streams to the remote collector (If that behaviour is undesirable, you will need to use win32trace directly.) To actually see the output as it is produced, start a DOS prompt, and run the file "win32traceutil.py" (eg, double-click on it from Explorer, or "python.exe win32traceutil.py") This will print all output from all other Python processes (that have imported win32traceutil) until you kill it with Ctrl+Break!)
So I decided you create something similar for IronPython. win32trace uses a memory mapped file for communication between the application and the trace collector. Since the only way I could find to use memory mapped files under CLI, relied on calls to unmanaged win32 api, I decided to use network UDP datagrams instead. Rather than writing something from scratch, I remembered a python script that I had used many years ago, creosote.py by Jeff Bauer. The original link to the script is broken, so I finally tracked a copy down in the Zope CVS. So I wrapped this code in a wrapper traceutil.py.
To use it, you just need to put this script in your IronPython or CPython path, and any output to stdout or stderr will be sent to the collector.
To start the collector:
ipy.exe traceutil.py
If the following code is run as a script by IronPython or CPython:
import traceutil
print "start"
a = "A"
# Create an error
import monty
the following would appear in the collector console running under .NET:
creosote bucket waiting on port: 7739
start
\n
Traceback (most recent call last):\r\n File E:\\IronPython\\IPCE-r4\\test_traceutil.py, line 6, in Initialize\r\n File , line 0, in __import__##4r\nImportErr
or: No module named monty\r\n
and the following would appear in the collector console running under Mono:
creosote bucket waiting on port: 7739
start
\n
Traceback (most recent call last):\n File test, line unknown, in Initialize\nImportError: No module named monty\n
Thursday, November 02, 2006
Microsoft Release FastCGI Technical Preview
To allow PHP to perform better with IIS, Microsoft have released a FastCGI component for IIS. Why is this good for Python Web apps? Many support FastCGI and if your web app/framework is WSGI compliant you can use flup. So we finally have Microsoft "blessed" way to get our Python apps to run behind IIS.
Tuesday, October 31, 2006
Roundup and WSGI
In a previous post I mentioned that I had an adaptor to run the Roundup Issue Tracker as a WSGI application. I never actually published the location of the code. So if you want to have a play, it can be found here. There are also 2 example ini files for using the adaptor with Paste.Deploy
Currently there is one unresolved issue: when using Roundup's internal authentication, after login the browser is not always re-directed correctly. This is not an issue for me as I use WSGI based authentication middleware.
10 Nov 2006
As of Roundup 1.3, Richard Jones has added a wsgi handler so I suggest you use that one instead.
Currently there is one unresolved issue: when using Roundup's internal authentication, after login the browser is not always re-directed correctly. This is not an issue for me as I use WSGI based authentication middleware.
10 Nov 2006
As of Roundup 1.3, Richard Jones has added a wsgi handler so I suggest you use that one instead.
Saturday, October 28, 2006
IronPython and ADO.NET Part 2
This is the second in a series of posts about database access with IronPython and ADO.NET. This post will discuss connecting to the database and executing basic DDL and SQL statements via the Python DB-API instead of directly accessing ADO.Net. So that the examples can run on Windows and non Windows systems, they will support either SQLite3 via the Mono.Data.SQLiteCilent ADO provider or Microsoft Access via the System.Data.Odbc provider.
The Python DB-API is a specification created by the Python Database SIG for a consistent interface to relational databases. For CPython there is at least one DB-API compliant library for most of the relational database engines that are used today. As part of his fepy project, Seo Sanghyeon has created a set of wrappers that provide DB-API support for MySQL, PostgreSql, SQLite, Microsoft SQL Server and ODBC ADO.NET database drivers. Since one of the features of ADO.Net is to also provide a consistent interface to relational databases, you may question why do you need to use another layer for database access with IronPython. The answer is simple, the DB-API allows you to focus on the actual access and manipulation of the data and hides the low-level ADO.Net setup and management code. To show how the DB-API can simpify your IronPython code, the examples from the first post of this series have been modified to use the DB-API.
If you want try the example or use the DB-API with IronPython you will need to install it. You can either download the modules from here and copy to the IronPython Lib directory or build and/or install the IronPython Community Edition which includes the DB-API.
Creating a table example
The first section of code is only required so the examples will work on either *ix or windows platforms. In normal usage, there is no need to import dbapi.py directly, just import the DB-API module for the database you want to use.
Comparing this code with the ADO.Net example you see that the opening of the database connection, and create a command instance is automatically done by the DB-API module. The Python DB-API PEP specifies implicit transactions that are started automatically and committed or rolled back on demand, so compared to ADO.Net example , a commit is required.
Load the data example.
Compared to the ADO.Net example, the DB-API allows the IronPython code to be simpler as it handles the creation of Parameters. (Note to self: MS Access, bulk inserts and transactions == very slow)
Select some data example.
Instead of using the ExecuteReader as in the ADO.Net example, the fetch method of the cursor instance is used to get the query result.
The Python DB-API is a specification created by the Python Database SIG for a consistent interface to relational databases. For CPython there is at least one DB-API compliant library for most of the relational database engines that are used today. As part of his fepy project, Seo Sanghyeon has created a set of wrappers that provide DB-API support for MySQL, PostgreSql, SQLite, Microsoft SQL Server and ODBC ADO.NET database drivers. Since one of the features of ADO.Net is to also provide a consistent interface to relational databases, you may question why do you need to use another layer for database access with IronPython. The answer is simple, the DB-API allows you to focus on the actual access and manipulation of the data and hides the low-level ADO.Net setup and management code. To show how the DB-API can simpify your IronPython code, the examples from the first post of this series have been modified to use the DB-API.
If you want try the example or use the DB-API with IronPython you will need to install it. You can either download the modules from here and copy to the IronPython Lib directory or build and/or install the IronPython Community Edition which includes the DB-API.
Creating a table example
The first section of code is only required so the examples will work on either *ix or windows platforms. In normal usage, there is no need to import dbapi.py directly, just import the DB-API module for the database you want to use.
import dbapi
try:
import sqlite3 as db
dbapi._load_type(db.assembly,db.typename)
connectstr = 'ip2country.db'
ip2country_create_table_ddl = '''
CREATE TABLE ip2country (
ipfrom INTEGER,
ipto INTEGER,
countrycode2 CHAR(2),
countrycode3 CHAR(3),
countryname VARCHAR(50),
PRIMARY KEY (ipfrom,ipto)
)
'''
except:
import odbc as db
dbapi._load_type(db.assembly,db.typename)
connectstr = 'DSN=ip2country'
ip2country_create_table_ddl = '''
CREATE TABLE ip2country (
ipfrom DOUBLE,
ipto DOUBLE,
countrycode2 CHAR(2),
countrycode3 CHAR(3),
countryname VARCHAR(50),
CONSTRAINT ip2country_pk PRIMARY KEY (ipfrom,ipto)
)
'''
Comparing this code with the ADO.Net example you see that the opening of the database connection, and create a command instance is automatically done by the DB-API module. The Python DB-API PEP specifies implicit transactions that are started automatically and committed or rolled back on demand, so compared to ADO.Net example , a commit is required.
dbcon = db.connect(connectstr)
cursor = dbcon.cursor()
cursor.execute(ip2country_create_table_ddl)
dbcon.commit()
dbcon.close()
Load the data example.
Compared to the ADO.Net example, the DB-API allows the IronPython code to be simpler as it handles the creation of Parameters. (Note to self: MS Access, bulk inserts and transactions == very slow)
dbcon = db.connect(connectstr)
import re
re_csv = re.compile(',(?=(?:[^\"]*\"[^\"]*\")*(?![^\"]*\"))')
cursor = dbcon.cursor()
insert_statement= '''
INSERT INTO ip2country (
ipfrom, ipto, countrycode2, countrycode3, countryname
) VALUES ( ?,?,?,?,? )
'''
f = open("ip-to-country.csv")
print "Loading..."
for line in f.readlines():
if line.endswith("\r\n"):
line = line[:-2] # remove \r\n
else:
line = line[:-1] # just remove \n
print line
ipf, ipt, cc2, cc3, cn = re_csv.split(line)
cursor.execute(insert_statement,(ipf[1:-1],ipt[1:-1],cc2[1:-1],cc3[1:-1],cn[1:-1]))
dbcon.commit()
f.close()
dbcon.close()
Select some data example.
Instead of using the ExecuteReader as in the ADO.Net example, the fetch method of the cursor instance is used to get the query result.
def ip2number(ipaddress):
'''
Convert dotted IP address to number
'''
A,B,C,D = ipaddress.split(".")
return (int(A) * 16777216) + (int(B) * 65536) + (int(C) * 256) + int(D)
dbcon = db.connect(connectstr)
cursor = dbcon.cursor()
try:
ipaddress = sys.argv[1]
# Convert dotted ip address to number
ipnumber = ip2number(ipaddress)
except:
print "Error - An IP Address is required"
sys.exit(1)
select_statement = '''SELECT * FROM ip2country
WHERE ipfrom <= %s AND ipto >= %s
''' % (ipnumber, ipnumber)
cursor.execute(select_statement)
row = cursor.fetchone()
print "The location of IP address %s is %s." % (ipaddress, row[4])
dbcon.close()
Friday, October 27, 2006
IronPython Community Edition R3 Released.
Yesterday Seo Sanghyeon announced that the third release of IPCE was available. This release uses the current IronPython stable version 1.0.1 and the modules of the CPython 2.4.4 standard library that are known to work under IronPython. Also Sanghyeon has been busy creating additional CPython-compatible wrappers which are included with this release:
You can download it from here or here.
- zlib, using System.IO.Compression.
- hashlib, using System.Security.Cryptography
- sqlite3, using generic DB-API module
You can download it from here or here.
Wednesday, October 18, 2006
Atom Publishing Server using WSGI
On XML.com "Joe Gregorio's latest Restful Web column implements the Atom Publishing Protocol as a Python web service using WSGI." Only discovered this today, hopefully the second part will be coming soon. Joe also has some other interesting wsgi related posts on his blog
Saturday, October 14, 2006
Adding .pth file support to IronPython
In a blog post I read, there was the following statement:
'Damnit. Apparently IronPython doesn’t support .pth files. I’m not sure if I should expect this or not from a “1.0” product, but it’s sure annoying since it seems most libraries use them.'
For me, it is an issue due the fact that many of the libraries I want to use come as Python Eggs, and the easy-install.pth file is required if you want them to work. So I decided to see what was needed to add .pth support to IronPython. In the end it was not too hard as the logic to add the contents of the pth files to the sys.path is included in the CPython site.py. It needed a little modification, but if you add this code to IronPython's site.py, .pth files work.
'Damnit. Apparently IronPython doesn’t support .pth files. I’m not sure if I should expect this or not from a “1.0” product, but it’s sure annoying since it seems most libraries use them.'
For me, it is an issue due the fact that many of the libraries I want to use come as Python Eggs, and the easy-install.pth file is required if you want them to work. So I decided to see what was needed to add .pth support to IronPython. In the end it was not too hard as the logic to add the contents of the pth files to the sys.path is included in the CPython site.py. It needed a little modification, but if you add this code to IronPython's site.py, .pth files work.
Sunday, October 08, 2006
Now running on Blogger Beta
Yesterday I moved this blog to run under the Blogger Beta. I had been running a test blog under it for the last month, and had suffered no show stopping issues. So made the decision to move yesterday and are now regretting it. The one thing I didn't test was the Atom feed with the various feed readers that subscribe to my blog. It would appear that pyblagg (the site most of my readers come via) doesn't see that the feed has been updated, so any posts created since the move are not being displayed. Do not have time to investigate at the moment, so created a feed using Feedburner in the hope that pyblagg can use this.
Using IronPython's 1.0.1 new community written built-in module support
In a previous post I mentioned the community written built-in modules support provided with IronPython 1.0.1. I remembered that Kevin Chu had posted a C# replacement for the CPython md5 library on the mailing list for inclusion in the IronPython core. His code is a perfect candiate for using the new external module loading support. So if you compile the code below as a library assembly
Mind you, if you compare the code for the C# implementation with Seo Sanghyeon's md5.py you can see why using IronPython with .NET or Mono makes a programmers life easier.
and create a DLLs directory in your IronPython 1.0.1 installation and copy the compiled assembly to it. When you start a new IronPython console, you be able to import md5 and use it like the CPython version.
using System;
using System.Collections.Generic;
using System.Text;
using IronPython.Runtime;
using System.Security.Cryptography;
using System.Runtime.InteropServices;
[assembly: PythonModule("md5", typeof(IronPythonCommunity.Modules.PythonMD5))]
namespace IronPythonCommunity.Modules
{
[PythonType("md5")]
public class PythonMD5
{
private MD5 _provider;
private readonly Encoding raw = Encoding.GetEncoding("iso-8859-1");
private byte[] empty;
public PythonMD5()
{
_provider = MD5.Create();
empty = raw.GetBytes("");
}
public PythonMD5(string arg)
: this()
{
this.Update(arg);
}
internal PythonMD5(MD5 provider)
: this()
{
_provider = provider;
}
[PythonName("new")]
public static PythonMD5
PythonNew([DefaultParameterValue(null)] string arg)
{
PythonMD5 obj;
if (arg == null)
obj = new PythonMD5();
else
obj = new PythonMD5(arg);
return obj;
}
[PythonName("md5")]
public static PythonMD5
PythonNew2([DefaultParameterValue(null)] string arg)
{
return PythonMD5.PythonNew(arg);
}
[PythonName("update")]
public void Update(string arg)
{
byte[] bytes = raw.GetBytes(arg);
_provider.TransformBlock(bytes, 0, bytes.Length, bytes, 0);
}
[PythonName("digest")]
public string Digest()
{
_provider.TransformFinalBlock(empty, 0, 0);
return raw.GetString(_provider.Hash);
}
[PythonName("hexdigest")]
public string HexDigest()
{
_provider.TransformFinalBlock(empty, 0, 0);
string hexString = "";
foreach (byte b in empty)
{
hexString += b.ToString("X2");
}
return hexString;
}
[PythonName("copy")]
public PythonMD5 Clone()
{
PythonMD5 obj = new PythonMD5(this._provider);
return obj;
}
}
}
>>> import md5
>>> md5
<module 'md5' (built-in)>
>>> m = md5.new()
>>> m.update("Nobody inspects")
>>> m.update(" the spammish repetition")
>>> m.digest()
u'\xbbd\x9c\x83\xdd\x1e\xa5\xc9\xd9\xde\xc9\xa1\x8d\xf0\xff\xe9'
Mind you, if you compare the code for the C# implementation with Seo Sanghyeon's md5.py you can see why using IronPython with .NET or Mono makes a programmers life easier.
Friday, October 06, 2006
Latest IronPython Releases
IronPython 1.0.1 released
IronPython 1.0.1 was released today. Apart from some minor bug fixes, it includes a new feature described in the release email as follows:
"The new support for community written built-in modules enables loading the .NET DLLs on startup and adding them to the built-in module list. This feature was implemented by updating site.py to check for a "DLLs" directory and looking for the PythonModuleAttribute point to an assembly. Now users can create built-in modules by simply adding this attribute to their assembly and re-distributing only the new assembly which the user can add to their DLLs directory."
The IronPython team say it is a small feature, but I believe it has greater implications. There has been much discussion on the mailing list about Microsoft not accepting community contributed code and when will missing CPython standard library module X that relies on a C extension be in the distribution. Now the community has another way to provide them.
IronPython Community Edition (IPCE)
A couple of weeks ago the busiest member of the IronPython community Seo Sanghyeon released a distribution of IronPython compiled under Mono. He has called this the IronPython Community Edition. As well as have a number of patches applied to the IronPython source that makes it work better under Mono, it comes with a substantial portion of the CPython standard library known to work under IronPython, CPython-compatible wrappers for .NET library:
md5, pyexpat, select, sha, socket, ssl, unicodedata, and the third party libraries - BeautifulSoup and ElementTree. He has also created a Sourceforge project for his IronPython modules and IPCE http://fepy.sourceforge.net/
IronPython 1.0.1 was released today. Apart from some minor bug fixes, it includes a new feature described in the release email as follows:
"The new support for community written built-in modules enables loading the .NET DLLs on startup and adding them to the built-in module list. This feature was implemented by updating site.py to check for a "DLLs" directory and looking for the PythonModuleAttribute point to an assembly. Now users can create built-in modules by simply adding this attribute to their assembly and re-distributing only the new assembly which the user can add to their DLLs directory."
The IronPython team say it is a small feature, but I believe it has greater implications. There has been much discussion on the mailing list about Microsoft not accepting community contributed code and when will missing CPython standard library module X that relies on a C extension be in the distribution. Now the community has another way to provide them.
IronPython Community Edition (IPCE)
A couple of weeks ago the busiest member of the IronPython community Seo Sanghyeon released a distribution of IronPython compiled under Mono. He has called this the IronPython Community Edition. As well as have a number of patches applied to the IronPython source that makes it work better under Mono, it comes with a substantial portion of the CPython standard library known to work under IronPython, CPython-compatible wrappers for .NET library:
md5, pyexpat, select, sha, socket, ssl, unicodedata, and the third party libraries - BeautifulSoup and ElementTree. He has also created a Sourceforge project for his IronPython modules and IPCE http://fepy.sourceforge.net/
Tuesday, September 19, 2006
Deploying the GDATA Reader as an executable revisited
In a previous post, I described how to create an executable with IronPython and provided a simple script to do it. I see that the IronPython team have released their own script Pyc to do the job. It can be found on the IronPython samples page.
Wednesday, September 06, 2006
IronPython1.0 Final Released Today
Tuesday, September 05, 2006
IronPython and ADO.NET Part 1
This is the first in a series of posts about database access with IronPython and ADO.NET. This post will discuss connecting to the database and executing basic DDL and SQL statements. So that the examples can run on Windows and non Windows systems, they will support either SQLite3 via the Mono.Data.SQLiteCilent ADO provider or Microsoft Access via the System.Data.Odbc provider.
Firstly we need some data to play with. A number of Python Web frameworks have been adding support for displaying the flag of the country against weblog comments. The country is identified from the remote IP address of the users browser. So we use IronPython to create a table and load it with the data from the ip-to-country cvs file which can be download from here. The full source of the IronPython script is here.
The first section of code references and imports the assemblies required for connecting and accessing the database. So the script can support either SQLite or Access, it tries to reference and import the SQLite ADO provider first, if this fails it then attempts to import the ODBC provider. The scripts uses an import alias so that we can refer to the database connection method by the same name independant of what ADO provider is being used. Also the database specific connection strings and table creation statements are defined here.
The full source of the IronPython script for loading the CSV data can be found here. We use the same code from the previous script to setup access to the data. The ip-to-country.csv file contains data of the following format:
Next the script opens the csv file and reads it line by line. After removing the line separator(s), the line is split into individual fields using the compiled regular expression. The value of each field is then assigned to the insert parameter with the delimiting double quotes removed. And the data is inserted into the ip2country table by calling the ExecuteNonQuery Method.
To run the script the ip-to-country.csv file must be in the current directory, and since it contains 65,000+ lines of data, it will take a while to run.
Now the ip2country table should contain some data we can query. Let's create a simple script that when passed an IP address, it prints the country location of the IP address. The source of the script can be found here.
To find the location, the script first converts the IP address to the numeric equivalent used in the ip2country data using the function ip2number. A SQL select statement is defined using the numeric ip address as the bounds for the where clause. Then an ExecuteReader instance is created and the results processed in a while loop.
The country name is accessed from row result by column number. I would prefer to get the value of the column via it's name e.g.
Hopefully this post has given you some insight in how to use IronPython with ADO.Net.
Firstly we need some data to play with. A number of Python Web frameworks have been adding support for displaying the flag of the country against weblog comments. The country is identified from the remote IP address of the users browser. So we use IronPython to create a table and load it with the data from the ip-to-country cvs file which can be download from here. The full source of the IronPython script is here.
Creating a table
The first section of code references and imports the assemblies required for connecting and accessing the database. So the script can support either SQLite or Access, it tries to reference and import the SQLite ADO provider first, if this fails it then attempts to import the ODBC provider. The scripts uses an import alias so that we can refer to the database connection method by the same name independant of what ADO provider is being used. Also the database specific connection strings and table creation statements are defined here.
The last section of the script, connects to the database, opens the connection and creates the table ip2country using the database specific DDL.
import clr
import System
clr.AddReference("System.Data")
import System.Data
try:
clr.AddReference("Mono.Data.SqliteClient")
from Mono.Data.SqliteClient import SqliteConnection as dbconnection
connectstr = 'URI=file:ip2country.db,version=3'
ip2country_create_table_ddl = '''
CREATE TABLE ip2country (
ipfrom INTEGER,
ipto INTEGER,
countrycode2 CHAR(2),
countrycode3 CHAR(3),
countryname VARCHAR(50),
PRIMARY KEY (ipfrom,ipto)
)
'''
except:
from System.Data.Odbc import OdbcConnection as dbconnection
connectstr = 'DSN=ip2country'
ip2country_create_table_ddl = '''
CREATE TABLE ip2country (
ipfrom DOUBLE,
ipto DOUBLE,
countrycode2 CHAR(2),
countrycode3 CHAR(3),
countryname VARCHAR(50),
CONSTRAINT ip2country_pk PRIMARY KEY (ipfrom,ipto)
)
'''
So once you run the script, you will either have an SQLite database ip2country.db or Access database ip2country.mdb with a single empty table called ip2country.
dbcon = dbconnection(connectstr)
dbcon.Open()
dbcmd = dbcon.CreateCommand()
dbcmd.CommandText = ip2country_create_table_ddl
dbcmd.ExecuteNonQuery()
dbcon.Close()
Load the data
The full source of the IronPython script for loading the CSV data can be found here. We use the same code from the previous script to setup access to the data. The ip-to-country.csv file contains data of the following format:
To parse each line of the csv file, a regular expression is used.
"33996344","33996351","GB","GBR","UNITED KINGDOM"
"50331648","69956103","US","USA","UNITED STATES"
"69956104","69956111","BM","BMU","BERMUDA"
import reRather than dynamically creating the SQL insert statement using string concatenation, the script uses variable placeholders in the insert statement and data parameters. In theory, this should be more efficent with the database only needing to prepare the insert statement once, and then binding the data parameters on each insert. But not sure if SQLite or Access does this type of optimisation. At least it means there will be no problems with country names like COTE D'IVOIRE that contain quotes.
re_csv = re.compile(',(?=(?:[^\"]*\"[^\"]*\")*(?![^\"]*\"))')
dbcmd = dbcon.CreateCommand()
insert_statement= '''
INSERT INTO ip2country (
ipfrom, ipto, countrycode2, countrycode3, countryname
) VALUES ( ?,?,?,?,? )
'''
# Create empty parameters for insert and attach to db command
p1 = dbparam()
dbcmd.Parameters.Add(p1)
p2 = dbparam()
dbcmd.Parameters.Add(p2)
p3 = dbparam()
dbcmd.Parameters.Add(p3)
p4 = dbparam()
dbcmd.Parameters.Add(p4)
p5 = dbparam()
dbcmd.Parameters.Add(p5)
dbcmd.CommandText = insert_statement
Next the script opens the csv file and reads it line by line. After removing the line separator(s), the line is split into individual fields using the compiled regular expression. The value of each field is then assigned to the insert parameter with the delimiting double quotes removed. And the data is inserted into the ip2country table by calling the ExecuteNonQuery Method.
f = open("ip-to-country.csv")
print "Loading..."
for line in f.readlines():
if line.endswith("\r\n"):
line = line[:-2] # running on a posix platform so remove \r\n
else:
line = line[:-1] # must be windows, just remove \n
print line
ipf, ipt, cc2, cc3, cn = re_csv.split(line)
p1.Value = ipf[1:-1]
p2.Value = ipt[1:-1]
p3.Value = cc2[1:-1]
p4.Value = cc3[1:-1]
p5.Value = cn[1:-1]
dbcmd.ExecuteNonQuery()
f.close()
dbcon.Close()To run the script the ip-to-country.csv file must be in the current directory, and since it contains 65,000+ lines of data, it will take a while to run.
ipy.exe load_op2country.py
Select some data
Now the ip2country table should contain some data we can query. Let's create a simple script that when passed an IP address, it prints the country location of the IP address. The source of the script can be found here.
To find the location, the script first converts the IP address to the numeric equivalent used in the ip2country data using the function ip2number. A SQL select statement is defined using the numeric ip address as the bounds for the where clause. Then an ExecuteReader instance is created and the results processed in a while loop.
dbcon.Open()
dbcmd = dbcon.CreateCommand()
try:
ipaddress = sys.argv[1]
# Convert dotted ip address to number
ipnumber = ip2number(ipaddress)
except:
print "Error - An IP Address is required"
sys.exit(1)
dbcmd.CommandText = '''
SELECT * FROM ip2country
WHERE ipfrom <= %s
AND ipto >= %s
''' % (ipnumber, ipnumber)
reader = dbcmd.ExecuteReader()
while reader.Read():
print "The location of IP address %s is %s." % (ipaddress, reader[4])
reader.Close()
dbcon.Close()
The country name is accessed from row result by column number. I would prefer to get the value of the column via it's name e.g.
print "The location of IP address %s is %s." % (ipaddress, row['countryname'])and this problem has been addressed by a Greg Stein's dtuple Python module. You will find a version of the find location script that uses dtuple here.
Hopefully this post has given you some insight in how to use IronPython with ADO.Net.
Saturday, September 02, 2006
Serving a Pylons App with ISAPI-WSGI
David Primmer has put together a great how-to on running a Pylons app with ISAPI-WSGI
http://pylonshq.com/project/pylonshq/wiki/ServePylonsWithIIS
And since Pylons uses Paste, it is a good how-to for running any Paste app under IIS.
And just out of interest, is anyone other than David and myself using isapi-wsgi?
http://pylonshq.com/project/pylonshq/wiki/ServePylonsWithIIS
And since Pylons uses Paste, it is a good how-to for running any Paste app under IIS.
And just out of interest, is anyone other than David and myself using isapi-wsgi?
Tuesday, August 29, 2006
Django with an IBM Informix backend
Update: This version of the django informix backend only works with Django pre 1.0 due to changes in Django database api. I have created a version that is known to work with Django 1.1+ and it's code can be found at: http://code.google.com/p/django-informix/
At work I needed to quickly be able to publish some technical bulletins on the web and provide a web interface for addition of new content. In the past we have used Zope for most of our in-house web development but I wanted the content stored in a "real" database. This meant deciding on a Python Web Framework that used a RDBMS out of the box. Part of the reason for selecting Django over the others, was the built-in database admin interface which meant one less set of controllers and views to develop.
Initial development was done using a SQLite backend and I had a working application deployed under lighty and fastcgi in just under a day. During this time I was also learning the framework so very impressed with the productivity. Of course good documentation and Google helped.
At work we deploy our applications on IBM Informix, Oracle and MS SQL Server databases, but for development and in-house projects use Informix. So I really needed a Django database adaptor for Informix. This would be my fourth Informix DA for a python project as I have written them for Zope2/3, and SQLObject. Writing the DA wasn't too hard but I had to do some interesting things with regular expressions to allow datetimes to work correctly and to remove some unsupported SQL syntax from the Django ORM created DDL. Also handling of TEXT data types is abit of a hack until I get a chance to re-factor the code. So if you are one of the few people in the world that still use Informix and want to use it with Django, I have put the code here. Due to Django's ORM, using some long table names you will have to use either Informix IDS 9 or 10.
At work I needed to quickly be able to publish some technical bulletins on the web and provide a web interface for addition of new content. In the past we have used Zope for most of our in-house web development but I wanted the content stored in a "real" database. This meant deciding on a Python Web Framework that used a RDBMS out of the box. Part of the reason for selecting Django over the others, was the built-in database admin interface which meant one less set of controllers and views to develop.
Initial development was done using a SQLite backend and I had a working application deployed under lighty and fastcgi in just under a day. During this time I was also learning the framework so very impressed with the productivity. Of course good documentation and Google helped.
At work we deploy our applications on IBM Informix, Oracle and MS SQL Server databases, but for development and in-house projects use Informix. So I really needed a Django database adaptor for Informix. This would be my fourth Informix DA for a python project as I have written them for Zope2/3, and SQLObject. Writing the DA wasn't too hard but I had to do some interesting things with regular expressions to allow datetimes to work correctly and to remove some unsupported SQL syntax from the Django ORM created DDL. Also handling of TEXT data types is abit of a hack until I get a chance to re-factor the code. So if you are one of the few people in the world that still use Informix and want to use it with Django, I have put the code here. Due to Django's ORM, using some long table names you will have to use either Informix IDS 9 or 10.
Thursday, August 17, 2006
IronPython 1.0 RC2 released
The Dynamic Languages team at Microsoft today released IronPython 1.0 RC2. I know what I will be testing for the next couple of nights. If no major issues found, looks like a final release in 2 weeks.
Monday, August 14, 2006
Deploying the GDATA Reader as an executable
Now that we have a working GDATA reader, it would be nice to make it into a CLI executable. IronPython provides a couple of ways to do this. The IronPython console application ipy.exe has an extension switch called SaveAssemblies. This will save the main Python script and any imported Python file as separate executables of the same basename. This is good if you have a simple single Python program that isn't dependent of other Python modules. Running the following command will create a gdatareader.exe in the same directory as the Python program.
You just need to provide the list of Python files and the name of the executable to be generated.
If you provide more than one Python file, the first file must contain the main logic. If the main logic is activated as follows:
this will need to be modified as the __name__ variable is set to the name of the executable without the .exe extension. The following works for me:
Modified versions of the GDATA reader scripts from the previous post are available. gdatareader.py gdatareaderrtf.py
ipy.exe -X:SaveAssemblies gdatareader.pyIt has a limitation that it will display a console window as well as the application when you run it. Also the IronPython team do not recommend it as the best way to create an executable. They recommend using the IronPython.Hosting.PythonCompiler class. I have created a simple Python script makeexe.py that uses this class to compile one or more Python files into a CLI executable. The executable is created as a true Windows application so there is no console. For both these methods, the created executable requires the gdata.dll, IronPython.dll and IronMath.dll assemblies in the same directory or in the GAC.
import sys
from IronPython.Hosting import PythonCompiler
from System.Reflection.Emit import PEFileKinds
from System.Collections.Generic import List
sources = List[str]()
for file in sys.argv[1:-1]:
sources.Add(file)
exename = sys.argv[-1]
compiler = PythonCompiler(sources, exename)
compiler.MainFile = sys.argv[1]
compiler.TargetKind = PEFileKinds.WindowApplication
compiler.IncludeDebugInformation = False
compiler.Compile()
You just need to provide the list of Python files and the name of the executable to be generated.
ipy.exe makeexe.py gdatareader.py gdatareader.exe
If you provide more than one Python file, the first file must contain the main logic. If the main logic is activated as follows:
if __name__ == "__main__":
this will need to be modified as the __name__ variable is set to the name of the executable without the .exe extension. The following works for me:
if __name __ == "__main__" or __name__ == sys.executable:
Modified versions of the GDATA reader scripts from the previous post are available. gdatareader.py gdatareaderrtf.py
Saturday, August 12, 2006
A Windows.Forms GUI for the GDATA Reader using IronPython
This is the second coding entry in a series of posts about using IronPython to develop a GDATA reader.
The purpose of this post is show how to add a GUI to the simple GDATA reader IronPython script I created in a previous post using System.Windows.Forms. It will not be an in depth discussion on how things work within Windows Forms. For a more detailed introduction to Windows Forms and IronPython, see Michael Foords excellent series of posts.
I suggest you open the source for the complete script in another browser window before continuing.
For the GUI we need a form and on the form, a textbox widget to enter the GDATA URI, a multi-line textbox widget to display the title and summary of each returned feed entry or any errors, a statusbar, and a button to re-fetch the feed.
To the original gdatareader.py script, we add references to the System.Windows.Forms and System.Drawing assemblies and import them.
Next we create a form class called GDataReaderForm.To design the form, I find it's easier to use the GUI Form Designer in Visual Studio 2003/2005 or Visual C# Express. I then copy the generated C# code for the form and with a couple of minutes of search/replace ( this to self, remove those pesky semi-colons and casts) and reformatting, I have the Python code to display my form. This is the _initgui method in the GDataReaderForm class.
Rather than explaining every widget property, I will just point out the things that I had to spend some effort on to get things to work.
Attached to the Click event of the Refresh button is the method GdataLoadFeed.
So when the Enter key is pressed or the Refresh button clicked, GdataLoadFeed is called, which inturn calls load_feed which finally calls parse the function created in the previous post to fetch and parse a GDATA feed. A list of entries is returned, formatted and displayed in the textbox.
The following screenshot shows the completed GUI displaying the Atom 1.0 feed from Jim Hugunin's blog running under Windows 2003 Terminal Server client (which explains the lack of a XP theme). The Atom feeds from blogs.msdn.com do not have a summary element so our script displays a blank line.
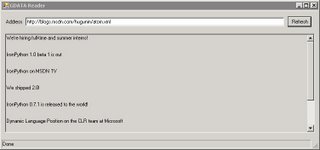
And the next screenshot is the same code running the GUI on Ubuntu 6.06 LTS with Mono 1.1.16.1.
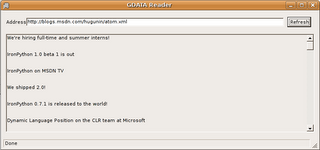
Improving the feed display with a RTF Textbox
Since a GDATA entry contains a link element it would be useful if it was displayed and a user could activate the link to view the entry content in a browser. Some more investigation of the gdata.dll was required to discover how to identify and access the link. The following function does the job for the GDATA reader:
The full source can be found here. The following screenshot shows the completed GUI with RichTextBox displaying the Atom 1.0 feed under Windows 2003 Terminal Server.
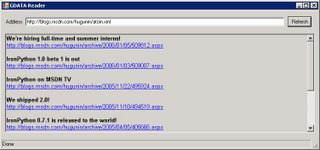
The functionality of the RichTextBox widget with the current Mono version of Windows.Forms means that the text formatting is not the same as .NET and the URL's are displayed but are not clickable. Hopefully this will be fixed soon.
The GUI is missing a couple of features like a top menu and About dialog, maybe that's something for another post.
In the next post we will compile the program into a CLI executable.
The purpose of this post is show how to add a GUI to the simple GDATA reader IronPython script I created in a previous post using System.Windows.Forms. It will not be an in depth discussion on how things work within Windows Forms. For a more detailed introduction to Windows Forms and IronPython, see Michael Foords excellent series of posts.
I suggest you open the source for the complete script in another browser window before continuing.
For the GUI we need a form and on the form, a textbox widget to enter the GDATA URI, a multi-line textbox widget to display the title and summary of each returned feed entry or any errors, a statusbar, and a button to re-fetch the feed.
To the original gdatareader.py script, we add references to the System.Windows.Forms and System.Drawing assemblies and import them.
Next we create a form class called GDataReaderForm.To design the form, I find it's easier to use the GUI Form Designer in Visual Studio 2003/2005 or Visual C# Express. I then copy the generated C# code for the form and with a couple of minutes of search/replace ( this to self, remove those pesky semi-colons and casts) and reformatting, I have the Python code to display my form. This is the _initgui method in the GDataReaderForm class.
Rather than explaining every widget property, I will just point out the things that I had to spend some effort on to get things to work.
- If the form is resized, we want the widgets to scale in relation to the re-sizing, so you need to set the Anchor property.
- If the Enter key is pressed, we want the program to fetch the URI, you need to set the AcceptsReturn property of the URI textbox to false. This means the Enter key with then activate the default button for the form. To make the Refresh button the default button, you need to set the AcceptButton property of the form.
self.AcceptButton = self.gdataRefreshButtonAttached to the Click event of the Refresh button is the method GdataLoadFeed.
self.gdataRefreshButton.Click += self.GdataLoadFeedSo when the Enter key is pressed or the Refresh button clicked, GdataLoadFeed is called, which inturn calls load_feed which finally calls parse the function created in the previous post to fetch and parse a GDATA feed. A list of entries is returned, formatted and displayed in the textbox.
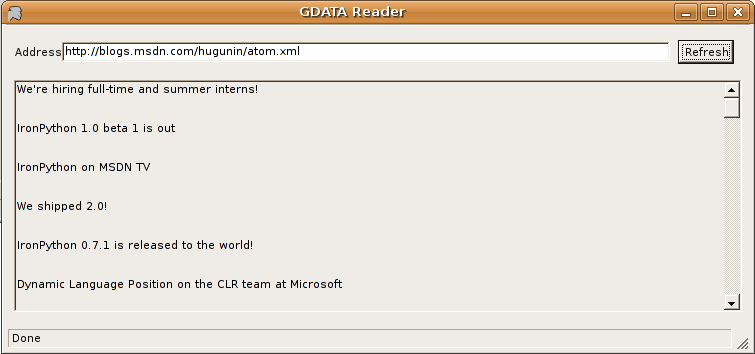
The following screenshot shows the completed GUI displaying the Atom 1.0 feed from Jim Hugunin's blog running under Windows 2003 Terminal Server client (which explains the lack of a XP theme). The Atom feeds from blogs.msdn.com do not have a summary element so our script displays a blank line.
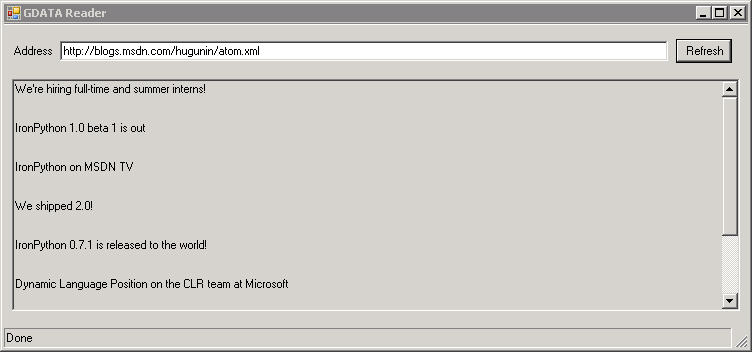
And the next screenshot is the same code running the GUI on Ubuntu 6.06 LTS with Mono 1.1.16.1.
Improving the feed display with a RTF Textbox
Since a GDATA entry contains a link element it would be useful if it was displayed and a user could activate the link to view the entry content in a browser. Some more investigation of the gdata.dll was required to discover how to identify and access the link. The following function does the job for the GDATA reader:
I discovered a RichTextBox widget will detect any urls in it's text if the DetectUrls property is set to true. So the the feed display TextBox was replaced with a RichTextBox, and the formatting function for the entry display replaced with a function that created RTF text. To handle a link being clicked the LinkClick event must have a function assigned to it.
def GetRelatedUri(self, entry, reltype="alternate"):
'''
Get the related uri of reltype from the GDATA entry Links collection.
Returns Uri or None if not found.
'''
uri = None
for link in entry.Links:
if hasattr(link, "Rel"):
if link.Rel == reltype:
uri = link.HRef.Content
else:
if reltype == "alternate":
# No Rel attribute means it's alternate
uri = link.HRef.Content
return uri
self.gdataEntriesRichTextBox.LinkClicked += self.LinkClicked
The code for the event handler:
def LinkClicked(self, sender, args):
'''
Get OS to launch the link using associated application
'''
System.Diagnostics.Process.Start(args.LinkText)
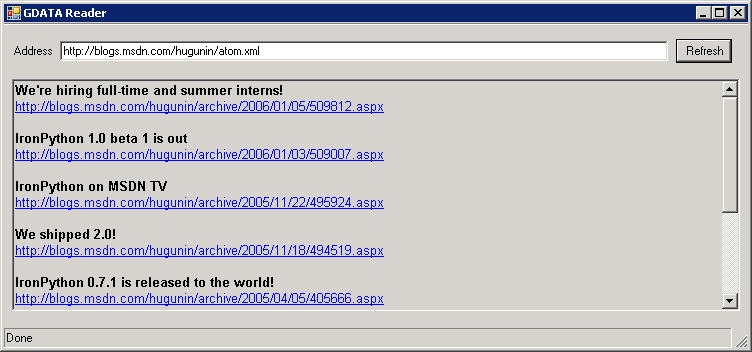
The full source can be found here. The following screenshot shows the completed GUI with RichTextBox displaying the Atom 1.0 feed under Windows 2003 Terminal Server.
The functionality of the RichTextBox widget with the current Mono version of Windows.Forms means that the text formatting is not the same as .NET and the URL's are displayed but are not clickable. Hopefully this will be fixed soon.
The GUI is missing a couple of features like a top menu and About dialog, maybe that's something for another post.
In the next post we will compile the program into a CLI executable.
Friday, August 11, 2006
My OSDC 2006 Paper Proposal Accepted
My paper proposal "Development of Mono Applications with Agile Languages" has been accepted for this years Open Source Developers Conference in Melbourne. There are 15 proposals for the Python stream, and lots of others. The accepted proposals for the conference can be viewed here. Great to see that Alan and Andy will be presenting as well.
So if you are into Open Source, want to spend time with like minded individuals and expand your mind, see you in Melbourne 6-8 December 2006. This will be my third year of attendance and I can highly recommend it.

So if you are into Open Source, want to spend time with like minded individuals and expand your mind, see you in Melbourne 6-8 December 2006. This will be my third year of attendance and I can highly recommend it.
My CLI and IronPython Development Environment
Someone asked me what my preferred development environment for doing CLI and IronPython work is. Since I want to use IronPython to develop cross-platform apps, my operating system is Ubuntu 6.06 LTS Linux running Mono 1.1.16.1. I normally have a couple of versions of IronPython installed, as of today it is 1.0 beta 9 and RC1. For editting I alternate between Vim 6.4 and the MonoDevelop 0.11 editor. To test my IronPython applications under Windows and to do graphical debugging, I either run Windows XP inside VMPlayer or access a Windows Terminal Server using the Linux Terminal Server Client. And of course I have CPython 2.4 installed to compare with the IronPython implementation and access the standard library.

Tuesday, August 01, 2006
Agile investigation of the GDATA client with IronPython
Updated 13 May 2007 - Modified for new location and packaging of GData libraries.
This is the first coding entry in a series of posts about using IronPython to develop a GDATA reader. You will need to have IronPython RC1 or better installed, and either .NET 2.0 or Mono 1.1.16.1+ installed.
Download the Google GDATA client and unarchive the contents.
Find Google.GData.Client.dll and copy it to the directory you will using for this project.
One of the powerful things you gain from using a dynamic interpreted language for software development is the ability to discover, try and test ideas without the dreaded edit, compile, and debug cycle. To do this we change to the directory with gdata.dll and launch an IronPython interactive console.
If you are using Mono, the command is:
The -X switches are not required but I find they make my life a little easier.
Now we have a console running let's load the Google GDATA client assembly
To load a non-standard assembly, I need to tell IronPython about it. This is done by importing the the clr module and calling the AddReference method. Now that IronPython knows about the GDATA assembly, I can import from it the Python way. From the API docs, I know the namespace.
This loads the client class with an alias of GDClient so I can save some keystrokes. Now we can inspect the class using some Python introspection tools.
Based on my reading of the API docs, I am interested in the Service and FeedQuery classes.
Using dir we are able to see the methods and properties of the Google.GData.Client Service and FeedQuery classes have. Another nice feature is .NET classes imported under IronPython have an auto-generated __doc__ property that shows the overloaded constructors for the class.
Now we can try to read a GDATA feed. So we need a website with a feed that is Atom 1.0 compliant, for this example we will use http://feedparser.org/docs/examples/atom10.xml
Since the Uri property of FeedQuery requires a .NET Uri type, we must import the CLR System module.
Now we can read the GDATA feed and iterate over the returned entries.
Based on this investigation of the GDATA client we can now create a simple python script to read a feed (Download).
Then run it from the commandline
Hopefully this post has given you an insight in how IronPython can help with .NET/Mono software development. In the next post we will give the GDATA reader a GUI to make it more useful.
This is the first coding entry in a series of posts about using IronPython to develop a GDATA reader. You will need to have IronPython RC1 or better installed, and either .NET 2.0 or Mono 1.1.16.1+ installed.
Download the Google GDATA client and unarchive the contents.
Find Google.GData.Client.dll and copy it to the directory you will using for this project.
One of the powerful things you gain from using a dynamic interpreted language for software development is the ability to discover, try and test ideas without the dreaded edit, compile, and debug cycle. To do this we change to the directory with gdata.dll and launch an IronPython interactive console.
ipy.exe -X:TabCompletion -X:ColorfulConsole -X:ExceptionDetailIf you are using Mono, the command is:
mono ipy.exe -X:TabCompletion -X:ColorfulConsole -X:ExceptionDetailThe -X switches are not required but I find they make my life a little easier.
Now we have a console running let's load the Google GDATA client assembly
IronPython 1.0.60725 on .NET 2.0.50727.42
Copyright (c) Microsoft Corporation. All rights reserved.
>>> import clr
>>> clr.AddReference("Google.GData.Client.dll")To load a non-standard assembly, I need to tell IronPython about it. This is done by importing the the clr module and calling the AddReference method. Now that IronPython knows about the GDATA assembly, I can import from it the Python way. From the API docs, I know the namespace.
>>> import Google.GData.Client as GDClientThis loads the client class with an alias of GDClient so I can save some keystrokes. Now we can inspect the class using some Python introspection tools.
>>> dir(GDClient)
['AlternativeFormat', 'AtomBase', 'AtomBaseLink', 'AtomBaseLinkConverter', 'AtomCategory', 'AtomCategoryCollection', 'AtomContent', 'AtomContentConverter', 'AtomEntry', 'AtomEntryCollection', 'AtomEntryConverter', 'AtomFeed', 'AtomFeedParser', 'AtomGenerator', 'AtomGeneratorConverter', 'AtomIcon', 'AtomId', 'AtomLink', 'AtomLinkCollection', 'AtomLogo', 'AtomParserNameTable', 'AtomPerson', 'AtomPersonCollection', 'AtomPersonConverter', 'AtomPersonType', 'AtomSource', 'AtomSourceConverter', 'AtomTextConstruct', 'AtomTextConstructConverter', 'AtomTextConstructElementType', 'AtomTextConstructType', 'AtomUri', 'BaseFeedParser', 'BaseIsDirty', 'BaseIsPersistable', 'BaseMarkDirty', 'BaseNameTable', 'ClientFeedException', 'ClientQueryException', 'ExtensionElementEventArgs', 'ExtensionElementEventHandler', 'FeedParserEventArgs', 'FeedParserEventHandler', 'FeedQuery', 'GDataGAuthRequest', 'GDataGAuthRequestFactory', 'GDataLoggingRequest', 'GDataLoggingRequestFactory', 'GDataRequest', 'GDataRequestException', 'GDataRequestFactory', 'GDataRequestType', 'GoogleAuthentication', 'HttpFormPost', 'HttpMethods', 'IBaseWalkerAction', 'IExtensionElement', 'IGDataRequest', 'IGDataRequestFactory', 'IService', 'LoggedException', 'QueryCategory', 'QueryCategoryCollection', 'QueryCategoryOperator', 'RssFeedParser', 'Service', 'TokenCollection', 'Tracing', 'Utilities', '__builtins__', '__dict__', '__name__']
>>>Based on my reading of the API docs, I am interested in the Service and FeedQuery classes.
>>> dir(GDClient.Service)
['Credentials', 'Delete', 'Equals', 'Finalize', 'GServiceAgent', 'GetHashCode', 'GetType', 'Insert', 'MakeDynamicType', 'MemberwiseClone', 'NewAtomEntry', 'NewExtensionElement', 'OnNewExtensionElement', 'OnParsedNewEntry', 'Query', 'QueryOpenSearchRssDescription', 'Reduce', 'ReferenceEquals', 'RequestFactory', 'StreamInsert', 'ToString', 'Update', '__class__', '__doc__', '__init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', 'add_NewAtomEntry', 'add_NewExtensionElement', 'remove_NewAtomEntry', 'remove_NewExtensionElement']
>>> GDClient.Service.__doc__
'Service()\nService(str applicationName)\nService(str service, str applicationName)\nService(str service, str applicationName, str library)'
>>>GDClient.FeedQuery.Uri.__doc__
'Get: Uri Uri(self)\nSet: Uri(self) = value\n'Using dir we are able to see the methods and properties of the Google.GData.Client Service and FeedQuery classes have. Another nice feature is .NET classes imported under IronPython have an auto-generated __doc__ property that shows the overloaded constructors for the class.
Now we can try to read a GDATA feed. So we need a website with a feed that is Atom 1.0 compliant, for this example we will use http://feedparser.org/docs/examples/atom10.xml
>>> query = GDClient.FeedQuery()
>>> import System
>>> query.Uri = System.Uri("http://feedparser.org/docs/examples/atom10.xml")
>>> service = GDClient.Service("cl","hexdump-gdatareader-0.1")
>>>Since the Uri property of FeedQuery requires a .NET Uri type, we must import the CLR System module.
Now we can read the GDATA feed and iterate over the returned entries.
>>> feed = service.Query(query)
>>> for entry in feed.Entries:
... print entry.Title.Text
...
First entry title
Based on this investigation of the GDATA client we can now create a simple python script to read a feed (Download).
import clr
import System
clr.AddReference("Google.GData.Client.dll")
import Google.GData.Client as GDClient
def parse(uri, nc=None):
# Create a query and service object
query = GDClient.FeedQuery()
service = GDClient.Service("cl","hexdump-gdatareader-0.1")
query.Uri = System.Uri(uri)
return service.Query(query)
if __name__ == "__main__":
feed = parse("http://feedparser.org/docs/examples/atom10.xml")
for entry in feed.Entries:
print entry.Title.Text,":",entry.Summary.Text
Then run it from the commandline
ipy.exe gdatareader.py
First entry title:Watch out for nasty tricksHopefully this post has given you an insight in how IronPython can help with .NET/Mono software development. In the next post we will give the GDATA reader a GUI to make it more useful.
Confessions of a part-time IronPython programmer
On the 27 july 2006 I gave a talk to the the Sydney Python Group (SyPy) about my experiences using IronPython on both .NET and Mono. I promised some people who couldn't attend that I would do a post on my blog that presented the same material. I have decided to present this material as a series of posts, with this post being the index to them.
Index of posts
Three months ago, I started trying to do "real" things with IronPython and I was disappointed with the results. This is because of my expectation that it would work like CPython and I would have access to the wonderful standard library. This is why people refer to Python as a language with batteries included. At the time dependant on your viewpoint, IronPython had only partially charged batteries and worst case batteries were not included. Yes, you could copy or link the CPython standard library so IronPython could use it, but of course modules that used C extensions will not work. Lot's of my favorite non-standard python modules are very dependant on the Python standard library. You would be surprised how many needed md5.py, and if you want to use Python's high level network libraries like urllib, httplib etc you need socket.py.
But it got better
As I said, this was a few months ago and things have improved, thanks to the IronPython team providing some standard library replacements written in C# and the community providing python wrappers round .NET classes. I also had my eureka moment where I discovered I had a good library at my disposal, the base and extension classes that both .NET and Mono provide.
So lets see what we can do with IronPython.
Requirements
We need something to build, so for the first series of posts we are going to create a quick and dirty GDATA reader. What is GDATA? From Google's website:
"The Google data APIs ("GData" for short) provide a simple standard protocol for reading and writing data on the web. GData combines common XML-based syndication formats (Atom and RSS) with a feed-publishing system based on the Atom publishing protocol, plus some extensions for handling queries."
Also Google provides a GDATA client written in C# as source and an assembly. We will use this client assembly as a helper module in our project. Three posts will document the steps in creating the GDATA reader.
Index of posts
- Agile investigation of the GDATA client with IronPython
- A Windows Form GUI for the GDATA reader with IronPython
- Deploying the GDATA Reader as an executable
- IronPython and ADO.Net Part 1
- IronPython and ADO.Net Part 2
- I have been programming in Python since 1997.
- Python is my favorite programming language.
- We use it at work as our cross platform scripting language and for most network/web work.
- I have played with IronPython since Jim Hugunin did the first public release and have experimented with most of the releases that have come from the Microsoft Dynamic Languages IronPython Team.
- Hope that IronPython will give me the same programming flexibility that the Mark Hammond's CPython win32 extensions gave me. But I want it on all platforms that support .NET and Mono.
Three months ago, I started trying to do "real" things with IronPython and I was disappointed with the results. This is because of my expectation that it would work like CPython and I would have access to the wonderful standard library. This is why people refer to Python as a language with batteries included. At the time dependant on your viewpoint, IronPython had only partially charged batteries and worst case batteries were not included. Yes, you could copy or link the CPython standard library so IronPython could use it, but of course modules that used C extensions will not work. Lot's of my favorite non-standard python modules are very dependant on the Python standard library. You would be surprised how many needed md5.py, and if you want to use Python's high level network libraries like urllib, httplib etc you need socket.py.
But it got better
As I said, this was a few months ago and things have improved, thanks to the IronPython team providing some standard library replacements written in C# and the community providing python wrappers round .NET classes. I also had my eureka moment where I discovered I had a good library at my disposal, the base and extension classes that both .NET and Mono provide.
So lets see what we can do with IronPython.
Requirements
- IronPython - At the time of writing this it is at RC1. The latest version can be downloaded from here.
- .NET 2.0 or Mono 1.1.16.1+
- Your favorite text editor
- And you may find an IDE like Visual Studio 2005, Visual Express C#, SharpDevelop or MonoDevelop helpful.
We need something to build, so for the first series of posts we are going to create a quick and dirty GDATA reader. What is GDATA? From Google's website:
"The Google data APIs ("GData" for short) provide a simple standard protocol for reading and writing data on the web. GData combines common XML-based syndication formats (Atom and RSS) with a feed-publishing system based on the Atom publishing protocol, plus some extensions for handling queries."
Also Google provides a GDATA client written in C# as source and an assembly. We will use this client assembly as a helper module in our project. Three posts will document the steps in creating the GDATA reader.
- Agile investigation of the GDATA client with IronPython
- A Windows.Forms GUI for the GDATA reader using IronPython
- Deploying the GDATA reader as an executable
- Embedding IronPython
- Database access with IronPython
- IronPython and the Web.
Wednesday, July 26, 2006
IronPython 1.0 RC1 released
It was announced on the IronPython mailinglist today, that the first release candiate of IronPython 1.0 is available for download. IronPython is an implementation of Python written in C# and designed to run on an implementation of CLI like Microsoft .NET 2.0 CLR or Mono 1.1.16.1+. The goal of the IronPython team is for 1.0 is to be compatible with CPython 2.4. But they have included some features from CPython 2.5 that are enabled with the -X:Python25 commandline switch. These include PEP 308: Conditional Expressions and PEP 343: 'with' statement.
As well as many bugfixes, the other positives for me are:
As well as many bugfixes, the other positives for me are:
- In some cases code execution is faster, and it launches 2.5 times faster.
- Since I do alot of my IronPython work with Mono, I can now finally exit using Control-D
Tuesday, July 18, 2006
Overriding IronPython's built-in modules
For those who haven't used IronPython, batteries are not included. After installing IronPython, you need to copy, symbolic link or update sys.path with the CPython standard libs if you want to do more than script .NET/Mono classes. As the various beta's of IronPython have been released, some of the standard library modules are being coded in C# and included in the IronPython Assembly. The socket module is one of these. But as of Beta 9, the socket module does not implement the getaddrinfo function. Many Python network modules expect this function and I was having trouble with a script I was trying to port because of it. But I knew that Seo Sanghyeon had written a IronPython socket module prior to it being included as a built-in and it had getaddrinfo. Since the calls to socket were in other third party python modules, I couldn't just rename socket.py and import it the new name. I needed to override the built-in but how? Then I remembered a post by Fuzzyman about including Python code in an assembly. So by using the code in the top of my script I was able to use the python version of socket.
Of course, there may be a better way.
import imp
import sys
moduleName = 'socket'
moduleSource = './Lib.ip/socket.py'
newModule = imp.new_module(moduleName)
execfile(moduleSource, newModule.__dict__)
sys.modules[moduleName] = newModule
import socket
Of course, there may be a better way.
SyPy Meetup Reminder Thursday 27 July
The Sydney Python group is having its first meeting for the year on Thursday July 27.
Usual time and new place:
Thursday, July 27, 2006 (6:30 PM - 8:30 PM)
The "new" University of Sydney School of IT Building.
Thanks to Bob Kummerfeld for arranging this.
The venue is approx 1 km from both Central and Redfern stations.
Use the entrance from the University side, not the Cleveland St side. If you come from City Rd, enter the Seymour Centre forecourt and follow the curve of the new building down to the foyer entrance.
http://www.cs.usyd.edu.au/~dasymond/index.cgi?p=Map
Please reply to this message (or click the appropriate radio button on http://upcoming.org/event/89388) if you will be coming.
Talks:
Graham Dumpeton on what is coming in the next major version of mod_python (3.3). This version of mod_python should represent a significant improvement over previous versions in certain areas with ramifications on stability. New features have also been added which make mod_python a bit more flexible than it is now and more useable in the way that Apache modules should be able to be used. Result is that mod_python can truly be used for more than just a jumping off point for stuff like WSGI and all those Python web frameworks that
keep popping up every day.
I will be giving a talk on my experiences in using IronPython with .NET and Mono.
The talks will be 15-20 minutes in length with plenty of time for questions.
Monday, July 17, 2006
IronPython and the moving API
Last week the IronPython team released IronPython .0 beta 9. This should be the last beta before the release candiate. Also they say they have finally locked down the Hosting API. This has an impact on what I have been working on, which involves hosting the interpreter within an ASP.NET handler. Thankfully the final Hosting API has returned to a more pythonic API rather than imho, the ugly API of beta 8.
With each beta release, there seem to be just enough changes in how to do things that writing an article on IronPython that will work with later beta's is a challenge. Even the IronPython team have been having trouble keeping their tutorials that ship with the beta in sync.
For example, on the IronPython mailinglist, Michael Foord pointed out a link to an article on IronPython. It is well written and has some interesting code examples that could attract a .NET programmer to give IronPython a go. I am not sure when the article was written but at least one code example doesn't work as a python list is no longer automatically converted to an array when passed as a argument to a .NET class. So to get this example to work for beta 9:
You need to modify the line:
You will also need to add
The author of the article provides the above syntax as an alternative solution, but as of beta 9 it's the only solution. I can understand why these changes have needed to happen so late in the beta programme, but it's a shame we miss a chance to bring more programmers under the spell of Python because the code didn't work.
With each beta release, there seem to be just enough changes in how to do things that writing an article on IronPython that will work with later beta's is a challenge. Even the IronPython team have been having trouble keeping their tutorials that ship with the beta in sync.
For example, on the IronPython mailinglist, Michael Foord pointed out a link to an article on IronPython. It is well written and has some interesting code examples that could attract a .NET programmer to give IronPython a go. I am not sure when the article was written but at least one code example doesn't work as a python list is no longer automatically converted to an array when passed as a argument to a .NET class. So to get this example to work for beta 9:
import clr
clr.AddReference("System.Windows.Forms")
from System.Windows.Forms import *
class MyForm(Form):
def __init__(self):
Form.__init__(self)
Button1 = Button()
Button1.Top = 10
Button1.Left = 10
Button1.Text = "One"
Button2 = Button()
Button2.Top = 50
Button2.Left = 10
Button2.Text = "Two"
ctrls = [Button1, Button2]
self.Controls.AddRange(ctrls)
f = MyForm()
Application.Run(f)
You need to modify the line:
ctrls = [Button1, Button2]to:
ctrls = System.Array[System.Windows.Forms.Control]( (Button1, Button2) )
You will also need to add
import Systemafter the
import clrline.
The author of the article provides the above syntax as an alternative solution, but as of beta 9 it's the only solution. I can understand why these changes have needed to happen so late in the beta programme, but it's a shame we miss a chance to bring more programmers under the spell of Python because the code didn't work.
Monday, July 10, 2006
What does the World Cup Football and OSDC 2006 have in common?
While watching the second half of today's final as Italy and France played towards a penalty shootout, I made the most of my time and submitted my paper proposal for OSDC 2006. If it is accepted I will be speaking about using Agile Languages in this case, IronPython and Boo with Mono.
Alan Green has submitted one, now just need Andy Todd to submit one, and the gang of 3 could be all speaking at OSDC again.
Alan Green has submitted one, now just need Andy Todd to submit one, and the gang of 3 could be all speaking at OSDC again.
Saturday, July 08, 2006
Another weblog to maintain
Friday, June 30, 2006
CLI - a journey of discovery
My open source interest has been focused on CLI for the last month, not the Command Line Interface but the Common Language Infrastructure. Thanks to mono there are tools to develop cross platform, cross language applications. As I am discovering the reality is a little different. So expect a few entries in this blog documenting the challenges, disappointments and victories as my journey of discovery continues. Maybe it's a good topic for OSDC 2006 paper.
Today I am an Australian
After living in Australia for the last 7 years, marrying an Australian, and creating a new little Australian, last night with 80 others, I attended my Australian citizenship ceremony. So another phase in my life begins.
Monday, May 29, 2006
OSDC 2006 Call for Papers
The Open Source Developers Conference is happening again this December in Melbourne, Australia. The last two conferences were excellent. Of course what makes a great conference is the people that attend and the content. The Call for Papers is now on.
I hope to attend this year but not sure if I will submit a paper proposal.
I hope to attend this year but not sure if I will submit a paper proposal.
Sunday, April 16, 2006
SQLAlchemy, more than an ORM
I remember seeing references to Michael Bayers' SQLAlchemy and thinking yet another Python ORM to look at sometime in the future. I have used SQLObject for various hobby projects, but since I deal with legacy databases (some database schema's just do not map well to an ORM) at the day job, I have tended to use SQL and the Python DBI for my database access work. Part of my job is to evaluate solutions to make my team more productive, and in reviewing where we allocate our time during development, I noted that a good portion is ensuring our SQL works across multiple RDBMS's. So I have been looking for Python solutions that abstract the creation of SQL against different RDBMS's. On investigating SQLAlchemy I was surprised to see that it you can use it to do exactly what I wanted. Also one of goals of Ian Bickings' SQL-API is to offer this functionality, but what follows is a discussion of how SQLAlchemy could help.
First connect to a database
Now describe the tables using using table metadata objects
First connect to a database
from sqlalchemy import *The option echo is set so we can view the generated SQL.
engine = create_engine("sqlite://filename=mydb",echo=True)
Now describe the tables using using table metadata objects
entries = Table('entries', engine,
Column('entry_id', Integer, primary_key = True),
Column('title', String(255), nullable = True),
Column('content', String(), nullable = True),
Column('status', String(10), nullable = False),
Column('creation_date', DateTime()),
Column('publish_date', DateTime())
)
comments = Table('comments', engine,
Column('comment_id', Integer, primary_key = True),
Column('entry_id', Integer, ForeignKey("entries")),
Column('comment', String(255), nullable = False),
Column('submitter', String(60), nullable = False),
Column('submit_date', DateTime())
)
# Create the tables
entries.create()
comments.create()
Now load some data. entries.insert().execute(entry_id=1,Get some data with a simple select with where clause and order by
title="My first blog entry",
content="A blogging I will go.....",
status="published",
creation_date="2006-04-17 08:15:30",
publish_date="2006-04-17 08:25:00")
entries.insert().execute(entry_id=2,
title="My second blog entry",
content="Another day, another blog entry....",
status="draft",
creation_date="2006-04-18 09:35:30")
comments.insert().execute(comment_id=1,
entry_id=1,
comment="The entry needs more substance.",
submitter="joe.blogger@home.net",
submit_date="2006-04-17 09:05:00")
comments.insert().execute(comment_id=2,
entry_id=1,
comment="I disagree with the first comment.",
submitter="jane.doe@rip.net",
submit_date="2006-04-17 09:05:00")
cursor = entries.select(entries.c.status=='published',Now a simple join
order_by=[entries.c.publish_date]).execute()
rows = cursor.fetchall()
for row in rows:
# Get column data by index
title = row[1]
# by column name
content = row['content']
# by column accessor
status = row.status
cursor = comments.select(comments.c.entry_id==entries.c.entry_id).execute()which generates the following SQL:
SELECT comments.comment_id, comments.entry_id, comments.comment,Of course, this quick overview only scratches the surface of what you can do with SQLAlchemy. It also has support for outer joins, subqueries, unions, updates and deletes. See here for more in depth documentation.
comments.submitter, comments.submit_date
FROM comments, entries
WHERE comments.entry_id = entries.entry_id
Friday, April 14, 2006
Pylons - another great tool for my programming toolkit
In a previous post I mentioned that I had been looking at Pylons, a WSGI enabled web framework and had a project that would be a good fit. Finally have found some time to start work on it and my experiences with Pylons so far have been good. I picked Pylons for a number of reasons:
- WSGI enabled
- Uses Paste
- Not aligned with any particular ORM
- Support of different template packages via Buffet
- Reasonable documentation to get you started
I originally had concerns about learning yet another template syntax - Myghty, Pylons default template package, but have found it easy enough to learn and use. So one of the reasons I choose Pylons - support of different template packages really has no substance. But some of the other things I have discovered while using Pylons certainly should be added to the reasons list. Both of them are re-implementations of Rails functionality.
As I progress with my project, I am sure there will be more posts about my Pylons experiences.
- Routes - makes it easy to create nice and concise URL's like http://timesheets.com/user/fred-smith/edit. No more ugly http://timesheets.com/user-edit.html?name=fred-smith
- WebHelpers - functions that simplify web development with template languages by providing common view patterns in re-usable modules. In addition to the Rails webhelpers, there helpers for HTML generation and pagination for collections and ORMs.
As I progress with my project, I am sure there will be more posts about my Pylons experiences.
Saturday, February 25, 2006
Getting ISAPI-WSGI from Subversion Repository
Had an anonymous email asking how to check-out isapi-wsgi from subversion. The following command will do it:
svn co http://svn.isapi-wsgi.python-hosting.com/trunk
svn co http://svn.isapi-wsgi.python-hosting.com/trunk
Thursday, February 23, 2006
Hex Dump Tools written in Python
In reviewing my blog access stats, it would appear that most used search engine keyword combination that sends visitors to my site are "hex" and "dump". So to not disappoint these 20% of visitors, I have tracked down a number of hex dumping tools written in my favorite programming language.
READBIN by Tony Dycks is a Text Console-based program which reads a single Input File specified on the command line one character at a time and prints out a formatted hex "dump" representation of the files contents 16 characters per display line. A prompt for continuation is issued after displaying 20 lines (320 characters of information). An entry of "X" or "x" followed by the key terminates the program execution. Any other entry followed by continues the display of the formatted hex and character information. A "." character is used for any non-displayable hex character
Hex Dumper by Sébastien Keim is a function which will display to stdout, the classic 3 column hex dump of a string passed to it.
Hexdump by Ned Batchelder prints a 3 column hex dump to stdout of a list of files or stdin.
READBIN by Tony Dycks is a Text Console-based program which reads a single Input File specified on the command line one character at a time and prints out a formatted hex "dump" representation of the files contents 16 characters per display line. A prompt for continuation is issued after displaying 20 lines (320 characters of information). An entry of "X" or "x" followed by the key terminates the program execution. Any other entry followed by continues the display of the formatted hex and character information. A "." character is used for any non-displayable hex character
Hex Dumper by Sébastien Keim is a function which will display to stdout, the classic 3 column hex dump of a string passed to it.
Hexdump by Ned Batchelder prints a 3 column hex dump to stdout of a list of files or stdin.
Thursday, February 02, 2006
What's been happening in the world of WSGI
Good to see some activity in the development of WSGI component based microframeworks.
I have been following Ben Bangert and James Gardners' work on Pylons which is based on Myghty, with a custom Resolver, full Paste and WSGI integration. Haven't had a play with it yet, but have an idea for a project where Pylons may be the perfect fit.
Also Julian Krause has just released RhubarbTart, a light object publishing web framework built on WSGI and Paste. It's object publishing model is similar to CherryPy. Since it built on Paste, RhubardTart makes the most of Paste's selection of WSGI middleware components to provide the other functionality expected of a web framework. So if have been using CherryPy because of it's ease in exposing object methods, but want to customise the component stack you use for a web project, have a look at RhubarbTart.
Then again, if you want to create your own WSGI/Paste framework, Ian Bickings has created a great tutorial to get you started. If you have a problem with understanding what WSGI/Paste is all about, read the tutorial, you will be enlightened.
And even Guido this week has nice things to say about WSGI - 'Maybe the current crop of Python web frameworks (as well as Rails BTW) have it all wrong. Maybe the WSGI folks are the only ones who are "getting" it.'
One of the joys of programming in Python is "batteries included" and the fact I get to pick which batteries to use to help me solve the programming task at hand. With WSGI I get the freedom to pick what components I want use in the HTTP request/response area for a web project, and get to focus on solving the actual programming problem or challenge.
I have been following Ben Bangert and James Gardners' work on Pylons which is based on Myghty, with a custom Resolver, full Paste and WSGI integration. Haven't had a play with it yet, but have an idea for a project where Pylons may be the perfect fit.
Also Julian Krause has just released RhubarbTart, a light object publishing web framework built on WSGI and Paste. It's object publishing model is similar to CherryPy. Since it built on Paste, RhubardTart makes the most of Paste's selection of WSGI middleware components to provide the other functionality expected of a web framework. So if have been using CherryPy because of it's ease in exposing object methods, but want to customise the component stack you use for a web project, have a look at RhubarbTart.
Then again, if you want to create your own WSGI/Paste framework, Ian Bickings has created a great tutorial to get you started. If you have a problem with understanding what WSGI/Paste is all about, read the tutorial, you will be enlightened.
And even Guido this week has nice things to say about WSGI - 'Maybe the current crop of Python web frameworks (as well as Rails BTW) have it all wrong. Maybe the WSGI folks are the only ones who are "getting" it.'
One of the joys of programming in Python is "batteries included" and the fact I get to pick which batteries to use to help me solve the programming task at hand. With WSGI I get the freedom to pick what components I want use in the HTTP request/response area for a web project, and get to focus on solving the actual programming problem or challenge.
Sunday, January 22, 2006
The Year in Review
Tomorrow my blog is one year old. So thought it was time to review it's value. In the last year I have made 44 posts, not quite once a week based on the math. But truthfully, I appear to blog in bursts directly related to when I am doing open source stuff. And since any open source work can only be done in my free time, which is hard to find as I try to balance life between work and family, there are large gaps of time between these bursts. I am in awe of the open source developers that seem able to hold down a day job, produce heaps of amazing code, and also update their blogs most days. Have these people discovered a secret source of free time, or can survive with 2 hours sleep a day, or maybe they are younger than me :-)
In reviewing what I have blogged about, it is great to see that the focus in the WSGI world has moved from server gateway implementations to frameworks and components that use it. In the future, I expect to write more posts on using WSGI and Paste as I implement systems at work using them.
Having a blog has hopefully improved my writing skills. When I started a year ago, my first posts were based on my thoughts, saved as drafts, then tweaked until they became coherent, then published. Now I find myself able to get these thoughts in something readable in the first attempt most of the time. Also having a blog means, other people leave comments and links to their blogs. This has meant greater exposure to others thoughts and experiences.
So this blog is of great value to me and hopefully the odd thought I have posted has been of value to someone else.
In reviewing what I have blogged about, it is great to see that the focus in the WSGI world has moved from server gateway implementations to frameworks and components that use it. In the future, I expect to write more posts on using WSGI and Paste as I implement systems at work using them.
Having a blog has hopefully improved my writing skills. When I started a year ago, my first posts were based on my thoughts, saved as drafts, then tweaked until they became coherent, then published. Now I find myself able to get these thoughts in something readable in the first attempt most of the time. Also having a blog means, other people leave comments and links to their blogs. This has meant greater exposure to others thoughts and experiences.
So this blog is of great value to me and hopefully the odd thought I have posted has been of value to someone else.
Sunday, January 08, 2006
Why is the PC running so slow?
At work we created a new VMWare image of the latest release of our Financial Software. Since it was required for a demo at our KL office, we needed to compress it prior to sending over the Internet to them. Since it was over 4GB, we used WinRAR to compress each virtual disk. It took forever and transferring via scp was just as bad. The cpu was the bottleneck, not because of the compression but the virus scanner scanning the VMWare image :-(. Morale of the story disable scanning for your VM image directories.
I guess a sign of times, were there are more background tasks running than "real" work being done in the foreground. And please, no comments about moving our work desktops to Linux or buying Mac's. Our server components are developed under Linux and run under most versions of Unix and Linux, but all our customers use M$ operating systems for the clientside. So we need to as well.
I guess a sign of times, were there are more background tasks running than "real" work being done in the foreground. And please, no comments about moving our work desktops to Linux or buying Mac's. Our server components are developed under Linux and run under most versions of Unix and Linux, but all our customers use M$ operating systems for the clientside. So we need to as well.
Subscribe to:
Posts (Atom)